classSolution { public: intnetworkDelayTime(vector<vector<int>>& times, int n, int k){ constint inf = INT_MAX / 2; vector<vector<int>> dist(n , vector<int>(n , inf)); for ( auto& t : times ) { int x = t[0] - 1; int y = t[1] - 1; dist[x][y] = t[2]; }
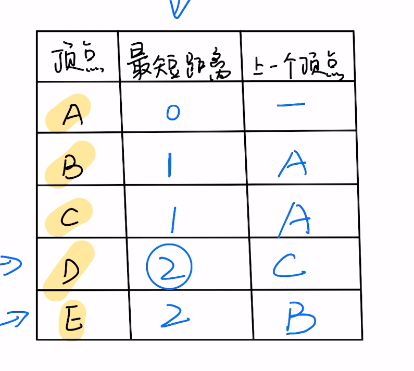
vector<bool> visited(n, false); for ( int num = 0; num < n; num++ ) { int pos = -1; int minn = INT_MAX; for ( int i = 0; i < n; i++ ) { if ( !visited[i] && ( minn > mindist[i] ) ) { // 找最小值 minn = mindist[i]; pos = i; } } visited[pos] = true;
for ( int i = 0; i < n; i++ ) { mindist[i] = min(mindist[i], mindist[pos] + dist[pos][i] ); } } int ans = *max_element(mindist.begin(), mindist.end()); return ans == inf ? -1 : ans; } };
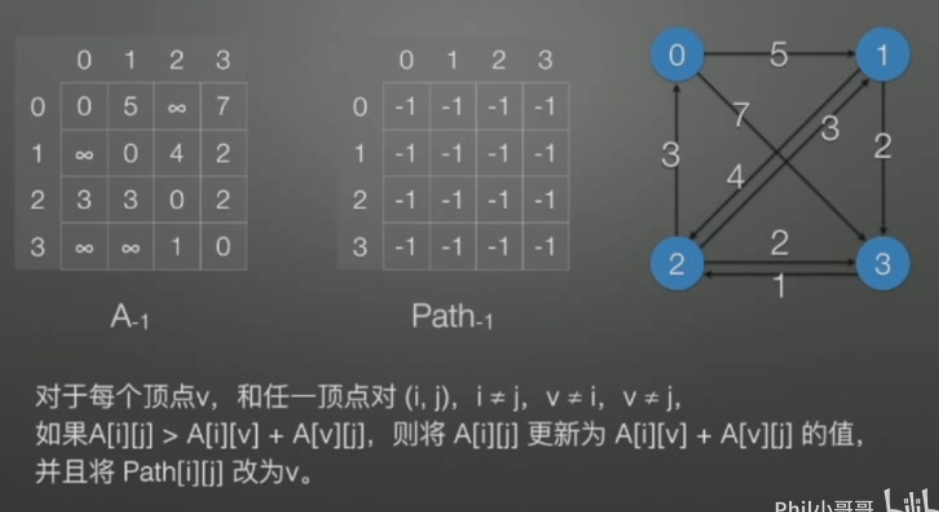
voidprintPath(int i, int j, int path[][max]){ // i = 1, j = 0 if ( path[i][j] == -1 ) { /*直接输出*/ }; else { int v = path[i][j]; // path[1][0] = 3 printPath(i, mid, path); // path[1][3] printPath(mid, j, path); // path[3][0] } }
// 外循环v为中间变量,Av,Pathv修改为v;内循环i,j ≠ v for ( int v = 0; v < n; v++ ) for ( int i = 0; i < n; i++ ) for ( int j = 0; j < n; j++ ) if ( A[i][j] > A[i][v] + A[v][j] ) { A[i][j] = A[i][v] + A[v][j]; path[i][j] = v; }
// LC 743 classSolution { public: intnetworkDelayTime(vector<vector<int>>& times, int n, int k){ vector<vector<pair<int, int>>> dist(n); // 存图方式 for ( auto& t : times ) { int x = t[0] - 1; int y = t[1] - 1; dist[x].push_back( make_pair(y, t[2]) ); }
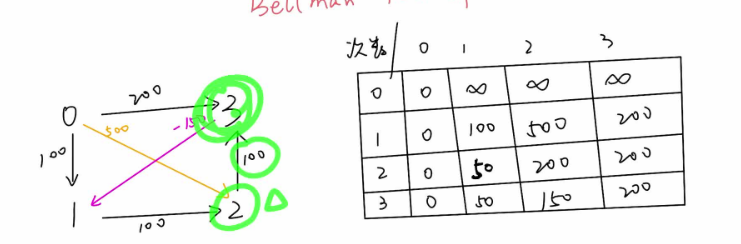
vector<int> mindist(n, INT_MAX); // |V| - 1 次 mindist[k - 1] = 0; // 初始化 bool finished; for ( int k = 0; k < n - 1; k++ ) {// n - 1 次 for ( int u = 0; u < n; u++ ) { // 前一节点 if ( mindist[u] == INT_MAX ) continue; for ( auto& [ v, weight ] : dist[u] ) { long newV = mindist[u] + weight; if ( newV < mindist[v] ) { mindist[v] = newV; finished = false; } } } if ( finished ) break; } int ans = *max_element(mindist.begin(), mindist.end()); return ans == INT_MAX ? -1 : ans; } };
classSolution { public: intfindCheapestPrice(int n, vector<vector<int>>& flights, int src, int dst, int k){ vector<vector<pair<int, int>>> dist(n); // 存图方式 for ( auto& t : flights ) { int x = t[0]; int y = t[1]; dist[x].push_back( make_pair(y, t[2]) ); } vector<int> mindist(n, INT_MAX); // |V| - 1 次 mindist[src] = 0; // 初始化 for ( int kk = 0; kk < k + 1; kk++ ) { vector<int> newdist(mindist); for ( int u = 0; u < n; u++ ) { // 前一节点 if ( mindist[u] == INT_MAX ) continue; for ( auto& [ v, weight ] : dist[u] ) { long newV = mindist[u] + weight; if ( newV < newdist[v] ) { newdist[v] = newV; } } } mindist.assign(newdist.begin(), newdist.end()); } return mindist[dst] == INT_MAX ? -1 : mindist[dst]; } };
voidbfs(Trie *trie, string s) { if (trie->isEnd) cout << s << endl; for (int i = 0; i < 26; i++) { if (trie->children[i] != nullptr) { string st = s; st += (i + 'a'); bfs(trie->children[i], st); } } }
intmain() { int N; cin >> N; string s; cin.ignore(); Trie *trie1 = new Trie(); for (int i = 0; i < N; i++) { getline(cin, s); trie1->insert(s); } getline(cin, s); if (trie1->startsWith(s)) //有这个前缀 { bfs(trie1->searchPrefix(s), s); } else { //没这个前缀 cout << "no" << endl; system("pause"); return0; } system("pause"); return0; }